
Lexikon
Das folgende (im Aufbau befindliche) Lexikon wichtiger inhaltsanalytischer Begriffe beruht auf dem Glossar der Fachtermini für computergestützte Inhaltsanalyse von Dr. Harald Klein (Vielen Dank für die freundliche Überlassung!). Es wurde und wird weiterhin um wichtige Begriffe erweitert. Hinweise auf Quellen finden sich in Klammern am Schluß eines Eintrages, die Literatur ist am Ende des Lexikons aufgeführt.
Bitte beteiligen Sie sich rege an der Gestaltung des Lexikons und weisen uns per mail auf Fehler, fehlende Begriffe usw. hin.
Zur besseren Orientierung benutzen Sie bitte die folgende Tabelle, mit der Sie jeweils an den ersten Begriff des betreffenden Anfangsbuchstabens gelangen. Sehr hilfreich kann auch die Verwendung der Suchen/Finden-Funktion (Strg+f) Ihres Browsers sein. Durch Klicken auf den kleinen Button (Pfeil nach oben), der sich jeweils am Anfang eines Buchstabens befindet, gelangen Sie an den Anfang des Lexikons (Buchstabe A).
Adjektiv: Eigenschaftswort, syntaktische Hauptkategorie.
Adverb: Wort, das sich auf die Art oder Zeit einer Handlung bezieht, syntaktische Nebenkategorie.
Affix: Ein Präfix oder Suffix (s. dort).
Ambiguität: Mehrdeutigkeit. Häufiges Probleme bei der Operationalisierung von Suchbegriffen bei computergestützten Inhaltsanalysen, da hier die Suchbegriffe nicht mehrdeutig sein dürfen.
Antonym: Wort mit entgegensetzter Bedeutung, z.B. schwarz-weiß, hell-dunkel.
Artikel: Determinierer, syntaktische Nebenkategorie, ein, eine, eines, der, die, das + Ableitungen.
Basic-Form: engl. für Grundform (s. dort).
Blank: Leerzeichen. Ein Wort kann von zwei Blanks - eines vorne und eines hinten - begrenzt werden.
CACA: (engl.) Abk., Computer-assisted content analysis, s.a. CUI
CAVE (Content Analysis of Verbal Explanations): Auf die Überlegungen Seligmans zu verschiedenen Attributionsstilen zurückgehende Technik, um inhaltsanalytisch Atributionsmuster (internal vs. external, global vs. spezifisch, stabil vs. instabil) zu erfassen. Lit.: Peterson, C. et.al. (1992): The explanatory style scoring manual. In: C. Smith (Ed.): Motivation and personality. S. 401-419. Cambrigde: University Press.
Character string: englisch für Zeichenkette (s. dort).
Cloze Prozedure: Verfahren zur Verständlichkeitsmessung. Aus einem Text wir jedes x-te Wort entfernt und eine Versuchsperson muss die fehlenden Worte ergänzen. Um so mehr Worte richtig ergaenzt werden, um so groesser ist die Verstaendlichkeit.
Codebuch: Wichtiges Hilfsmittel bei manuell durchgeführten Inhaltsanalysen. Hier werden durch die Kodierer alle Kodierungen standardisiert erfaßt. Das C. sollte allgemeine Hinweise zur Kodierung, spezielle Hinweise (z.B. Nummern bestimmter Analyseeinheiten), das vollständige Kategoriensystem und die
Kategoriendefinitionen enthalten.
Content Analysis: engl., s. b. Inhaltsanalyse.
CUI: Abkürzung für computerunterstützte Inhaltsanalyse, wird auch oft elektronische Inhaltsanalyse oder maschinelle Inhaltsanalyse genannt. Für die C. existieren zahlreiche Programme, z.B. CoAn für Windows, s.a. auf der Software-Seite.
Datengenerierung: Die Datengenerierung dient dazu, einen Text zu digitalisieren (maschinenlesbar) zu machen. Zur Zeit ist das durch Abtippen, Scannen oder Diktieren des Textes möglich.
DAW: Dresdner Angstwörterbuch. Von Berth (seit 1997) entwickelte deutschsprachige Computerversion der Gottschalk-Gleser-Angstskalen. (s. bei Gottschalk-Gleser und auf der DAW-Seite.
Denotation: rein sachlicher Bedeutungsgehalt eines Wortes, z.B. "Auto"=Fortbewegungsmittel mit vier Rädern, s.a. Konnotation.
Derivationsmorphologie: Bereich der Grammatik mit Regeln, wie neue Wörter aus bekannten zu erzeugen sind. Bsp:: Inhalt + Analyse = Inhaltsanalyse (1)
Determinierer: Artikel u.ä. Wörter wie ein, die, einige; syntakt. Nebenkategorie (1)
Diktionär: Gleichbedeutend mit Kategorienschema. Ein Diktionär enthält alle
Suchbegriffe, die die Kategorien operationalisieren. Manchmal wird Diktionär
auch im Sinne von Wörterliste, Wörterbuch gebraucht.
Diphtong: Vokal, der aus zwei unmittelbar aufeinanderfolgenden Vokalen besteht, z.B. EE in See, EI in Leiter oder EU in Beute.
Disambiguierung: Verfahren oder Arbeitstechnik, die Ambiguität oder Mehrdeutigkeit von Suchbegriffen in Eindeutigkeit zu überführen.
Discomfort-relief-quotient: (DQR), Verfahren zur Messung von Motivationen. In einer Analyseeinheit werden die stressinduzierenden Worte (d) und die entspannungsinduzierenden Worte (r) ausgezaehlt. Der DQR wird dann bestimmt nach d/(d+r). (3).
Diskurs: Abfolge aufeinanderbezogener Sätze. D.-Analysen suchen nach Regeln in solchen Abfolgen.
Dota-Verfahren: Verfahren zur Messung von kognitiven Schließungstendenzen. Mit CoAn für Windows sind Analysen nach dem DOTA-Verfahren einfach und zuverlässig möglich. Literatur: Ertel, S. (1972): Erkenntis und Dogmatismus, Psychologische Rundschau, 23, S. 241-269.
EVA: Elektronische Verbal-Analyse, erstes deutschsprachige Inhaltsanalysesoftware (1973). Literatur: Grünzig, H.-J., Holzscheck, K. & Kächele, H. (1976): EVA - Ein Programmsystem zur maschinellen Inhaltsanalyse von Psychotherapieprotokollen. Medizinische Psychologie. 2, S. 208-217.
Flexionsmorphologie: Modifikation der Form eines Wortes gemäß seiner Rolle im Satz (1).
Flesh-Formel: Formel zur Bestimmung der Lesbarkeit/Verständlichkeit eines Textes
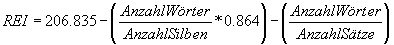
Fremdwort: Zeichenketten, die etymologisch aus einem anderen Sprachraum stammen. Sie sind z. B. bei der Bestimmung von Lesbarkeits- bzw. Verständlichkeitsmaßen (s. dort) von Bedeutung.
Frequenzanalyse: Verfahren, bei dem Bedeutungsstrukturen (nur) über die Häufigkeitsverteilung bestimmter Kategorien bestimmt wird.
General Inquirer: Eine der ersten, wenn nicht die erste, Inhaltsanalysesoftware. Lit.: Stone, P.J. et. al. (1966): The General Inquirer. Cambrigde, M.A.: MIT Press.
Gießener Sprachanalyse: aus der Psychotherapieforschung stammendes Verfahren zur Interviewauswertung. Es wird gemessen wie lange, wer, in welcher Abfolge in einem solchen Interview spricht (Interviewer, Patient bzw. Schweigen) und dies dann anhand eines standardisiertem Kategoriensystem computergestützt ausgewertet. Lit.: Brähler, E. (1975): Die Erfassung des Interventionsstils von Therapeuten durch die automatische Sprachanalyse. Diss. Universität Gießen.
Grammatik: Menge von Regeln, die Form und Bedeutung von Worten und Sätzen in einer bestimmten Sprache festlegt.
Grundform: Worte in ihrer unflektierten Form, d.h. Infinitv bei Verben (z.B. "gehen" statt "gehe, ging, gegangen"), Nominativ Singular bei Substantiven (z.B. "Haus" statt "Häuser, Hauses") und Positiv bei Adjektiven (z.B. "schön" statt "schöner, am schönsten.")
Gottschalk-Gleser: Quantitatives Verfahren zur Messung von Affekten im weitesten Sinne (Angst, Aggressivität, Depression, Schizophrenie, Hoffnungslosigkeit u.a.), vielfältig eingesetzt z.B. im Bereich der Psychosomatik. s.a. bei DAW. Lit.: Gottschalk, L.A. & Gleser, G.C. (1969): The Measurement of Psychological States Trough the Content Analysis of Verbal Behavior. Berkeley: University of California Press., Homepage Louis A. Gottschalk.
Graphologie: Methode für die Untersuchung und Deutung der Handschrift, mit der auf besondere (Persönlichkeits-) Eigenschaften des Schrifturhebers geschlossen werden soll. Sehr umstritten bzgl. der Gütekriterien. Lit.: Wallner, T. (1998). Lehrbuch der Schriftpsychologie. Grundlegung einer systematisierten Handschriftendiagnostik. Heidelberg: Asanger.
Hapax legomena: Eine Zeichenkette oder Wort, die nur einmal in einem Text oder Dokument vorkommt. H.L. können als wesentliche Stilmerkmale des Textverfassers betrachtet werden.
Hauptverb: Alle Verben außer Hilfsverben.
Hilfsverb: Verbart, mit der Konzepte ausgedrückt werden, die sich auf die Wahrheit des Satzes beziehen, wie Tempus, Negation, Frage/Aussage, notwendig/möglich (1).
Homograph: s. Homonym.
Homonym: Zeichenkette (Wort), die mehrere gegensätzliche Bededeutungen hat. Beispiele: a) Bank, Bedeutung: Kreditinstitut oder Sitzgelegenheit, b) Mutter, Bedeutung: Teil einer Schraube oder nahe Verwandte.
Hypertext: nicht lineare Repräsentation von Informationen in einem Netzwerk aus Knoten und Verknüpfungen. Bsp.: Dieses Lexikon (die einzelnen Begriffe sind Knoten und die dort aufgeführten Verweise auf andere Begriffe sind die Verknüpfungen) oder diese Domain.
Infix: Eine Zeichenkette die an beliebiger Stelle in einem
Wort vorkommen kann. Steht ein Infix am Anfang einer Zeichenkette, heißt es Präfix, steht es am Ende einer
Zeichenkette, heißt es Suffix. Im strengeren Sinne dürfen Infixe nicht am Anfang oder Ende einer Zeichenkette stehen (also nicht Präfix oder Suffix sein)
Inhaltsanalyse: "Inhaltsanalyse ist eine Methode zur Erhebung sozialer Wirklichkeit, bei der von Merkmalen eines manifesten Textes auf Merkmale eines nichtmanifesten Kontextes geschlossen wird." (Merten, 1995, S. 59).Vorteile der Inhaltsanalyse: (aus Früh, 1998, S. 39f.): "Die Inhaltsanalyse erlaubt Aussagen über Kommunikatoren und Rezipienten, die nicht, bzw. nicht mehr erreichbar sind.,
Der Forscher ist nicht auf die Kooperation von Versuchspersonen angewiesen., Der Faktor Zeit spielt für die Untersuchung eine untergeordnete Rolle, man ist nicht an bestimmte Termin zur Datenerhebung gebunden.,
Es tritt keine Veränderung des Untersuchungsobjektes durch die Untersuchung auf.,
Die Untersuchung ist beliebig reproduzierbar oder mit einem modifizierten Analyseinstrument am selben Gegenstand wiederholbar.,
Inhaltsanalysen sind meist billiger als andere Datenerhebungsmethoden."
Mit dem Problem der Definition von "Inhaltsanalyse" beschäftigen sich recht ausführlich: Shapiro, G. & Markoff, J. (1997): A Matter of Definition. In: C.W. Roberts (Ed.) Text Analysis for the Social Sciences. S. 9-31. Mahwah, N.J.: Erlbaum.
Intra-Rater-Reliabilität: auch Intra-Coder-Reliabilität, Übereinstimmung der Kodierungen eines Kodierers an einem Text zu zwei Zeitpunkten.
Inter-Rater-Reliabilität: auch Inter-Coder-Reliabilität, Gütekriterium. Grad der Übereinstimmung der an einem Text vorgenommenen Kodierungen von zwei (oder mehr) unabhängigen Kodierern. Berechnet nach R= 2Ü/(C1+C2), wobei R=Reliabiliät, Ü=Anzahl der übereinstimmenden Kodierungen, C1= Anzahl der Kodierungen des ersten Kodierers, C2=Anzahl der Kodierungen des zweiten Kodierers (nach (2)). Merten (1995) unterscheidet drei Typen: a) Prüfung der paarweisen Übereinstimmung von 2 (von n) Codierern, b) Prüfung der Übereinstimmung bei allen n Codieren (Schnittmenge) und c) Prüfung, wie sich die Mehrheit der Codierer verhält. Als akzeptable Werte für die I. gibt er an: 0.8 für syntaktische Variablen, 0.7 für semantische Variablen und 0.6 für pragmatische Variablen.
Isotopieebene: Sinnabschnitt, Leitthema. Inhalticher "roter" Faden eines Texts (2).
Kategorie: Operationalisierung eines theoretisches Konstruktes mit Suchbegriffen. Eine Kategorie "Verwandte" könnte z. B. Suchbegriffe enthalten wie: Mutter, Vater, Onkel, Tante, Oma, Opa, Bruder, Schwester usw.
Kategoriensystem: Zusammenfassung mehrerer Kategorien entsprechend der Fragestellung. K. sollten folgenden Anforderungen genügen (3): Sie sollten a) theoretische begründet sein, b) vollständig sein, c) sich gegenseitig ausschließen, d) voneinander unabhängig sein, e) einheitlich gestaltet sein und d) nicht mehrdeutig sein.
Klassem: Sem aus dem Kontext eines Zeichens (eines anderen Sems), das zum Verständnis wichtig sein kann.
Kodierer: Geschulte Person, die anhand eines definierten Kategoriensystems die Kodierung (Analyse) eines Texts vornimmt.
Kohärenz: Sinnkontinuität eines Textes, die pragmatische (sinnmachende) Abfolge der Sätze. Berechnung: d/(c-1)*100%, wobei d=Summe der fehlenden Kohärenzfragen und c=Anzahl der Sätze. Lit.: Tress, W. et.al. (1984): Zur Patholinguistik schizophrener Texte. Nervenarzt, 55, S. 488-495.
Kohäsion: Bezeichnung für grammatikalische Abhängigkeiten im Oberflächentext, syntakmatische Beziehungen zwischen den Textelementen. Berechnung: (a-b)/c*100%, wobei a=Summe der kohäsionsstifenden Textstellen, b=Anzahl der thematischen Kategorien und c=Anzahl der Sätze. Eine K. von 0% ensteht, wenn viele inhaltlich (thematisch) nicht zusammenhängende Sätez aneinandergereiht werden.
Kompositum: Wort das aus mehreren anderen Worten zusammengesetzt ist, z.B. Inhaltsanalyse.
Konjunktion: syntaktische Nebenkategorie, die Wörter wie und, oder, aber umfaßt. (1).
Konkordanz: aus der Linguistik, Index zu den Wörtern eines Textes, auch im Sinne KWIC (s. dort) gebraucht.
Konnotation: emotional affektive Beibedeutung eines Wortes, z.B. "Karre" als abwertende Bezeichnung für "Auto", s. a. Denotation
Kontext: Umgebung einer Zeichenkette, eines Wortes. Der K. wird herangezogen zur Disambiguierung oder Monosemierung. Man kann zwischen intratextuellen K. (alle anderen Zeichen in einem Text) und extratextuellen Kontext (über den eigentlichen Text hinausgehende Informationen, z.B. über den Verfasser, der Art der Textenstehung usw.) unterscheiden.
Kontexteinheit: bestimmte Größe eines Kontextes. Die K. legt fest, wieviele Worte in der Umgebung des Suchausdrucks bei KWIC (computerunterstützte Inhaltsanalyse) angegeben werden bzw. wieviele Worte um den Suchausdruck herum beim manuellen
Inhaltsanalysen durch den Kodierer genutzt werden dürfen zur Monosemierung/Disambiguierung (s. dort).
Kontigenz: gemeinsames, überzufälliges Autreten von Symbolen in einer zu untersuchenden Texteinheit, z.B. könnte betrachtet werden, wie oft das Wort "Bundeskanzler" gemeinsam mit Adjektiven wie "fleißig" oder "faul" auftritt.
Korpus: geordnete Menge von Texten, die nach einem gemeinsamen Merkmal zusammengefaßt wurden. Als Merkmale zur Korpusbildung können inhaltliche (Bsp.: Der Wendekorpus des IDS, der verschiedene Textsorten aus der Zeit der Wende in der DDR enthält) oder formelle Aspekte (z.B. alle Texte von Shakespeare oder alle Artikel einer Zeitung aus einem bestimmten Zeitraum) herangezogen werden.
KWIC: Keyword in Context. Analysemöglichekeit bei computergestützten Inhaltsanalysen, bei der die Suchbegriffe (keywords) in ihren Textumgebung (Kontext) dargestellt werden.
Lasswell-Formel: "Who says what in which channel to whom with what effect", Kommunikationsmodell. Harold D. Lasswell wird verschiedentlich als "Vater der Inhaltsanalyse" bezeichnet. (3)
Lesbarkeit: Verständlichkeit, Readability, s. z.B. bei Flesh-Formel
Lexem: Wort, bei ling. Textanalysen Wort in seiner isolierten Bedeutung.
Linguistik: Wissenschaft, die sich mit dem Aufbau und der Funktion von Sprache beschäftigt, s.a. Psycholinguistik.
Mehrdeutigkeit: s. Ambiguität, s. Disambiguierung
Metapher: symbolisierende Umschreibung für ein anderes Wort, Substitution ein oder mehrerer Seme, wobei es eine gemeinsame Schnittmenge gibt (3).
Metonymie: Be-/Umschreibung für ein anders Wort/Zeichen/komplexe Bedeutungsstruktur ohne gemeinsame semantische Schnittmenge, z.B. "Wallstreet" für die amerikanische Börse (3).
Modalverb: Unterart der Hilfsverben: können, sollen, wollen, mögen, dürfen. (1)
Memo: bei qualitativen Analysen, Anmerkung zu einer Textstelle im Originaltext (im weitesten Sinne). Programme zur qualit. Analyse helfen bei der Erstellung, Verwaltung und Strukturierung von M. und zur Generierung von Erkenntnissen aus den M.
Monosemierung: Bedeutungspräzierung bestimmter Zeichenketten, Wörter, komplex. Ausdrücke (bei ling. Textanalysen), geschieht meist durch (strukturelle) Betrachtung des Kontextes.
Morphem: Kleinste bedeutungstragende Einheit in die sich Worte aufspalten lassen, Bsp: In-halts-ana-lyse.
Morphologie: Bestandteil der Grammatik, die festlegt, wie aus Morphemen Wörter zusammengesetzt werden.
Nomen: syntaktische Hauptkategorie, die Wörter umfaßt, die ein Ding oder eine Person bezeichnen (Substantiv). (1).
Objektive Hermeneutik: Von Oevermann entwickelte Methode der qualitativen Textauswertung. Eine kurze Einführung findet man in: Reichertz, J. (1995): Die objektive Hermeneutik - Darstellung und Kritik. In: E. König & P. Zedler (Hrsg.): Bilanz qualitativer Forschung. Band II. S. 379-423. Weinheim: Deutscher Studien Verlag.
OCR: Optical Character Recognition. Maschinelles (computergestütztes) Einlesen von gedruckten Text in Textverarbeitungssysteme. Ein bekanntes und ausgereiftes Programm ist z.B. OmniPage.©
Parsen: auch Parsing, morphologische Analyse eines Satzes/Textes, bei der die enthaltenen Worte auf ihre grammatischen Grundformen (syntaktische Kategorien) zurückgeführt werden und Subjekt, Prädikat, Objekt usw. (Abhägigkeiten der Textelemente) bestimmt wird. Für das P. existiert einige Software.
Part-of-speech-tagging: s. tagging.
Polysem: vieldeutiges Zeichen, s.a. Homonym, Homograph, Polysemie.
Polysemie: Vieldeutigkeit.
Präfix: Zeichenkette, die am Anfang eines Wortes steht. Bei computergestützten Inhaltsanalysen kann es auch ein einzelner Buchstabe (oder ein anderes Zeichen) sein.
Präposition: Worte, die typischerweisee auf eine räumliche oder zeitliche Beziehung referieren wie in, auf, an, bei ,durch; syntaktische Hauptkategorie (1).
Präsupposition: Selbstverständliche (implizite) Sinnvoraussetzungen sprachlicher Ausdrücke bzw. Äußerungen. (2)
Pragmatik: Die P. beschäftigt sich mit der Untersuchung der Verwendung der Sprache im sozialen Kontext (1), Relation der Zeichen zu ihren Benutzern (3).
Pro-Form: Wortform, die im fortlaufenden Text für einen anderen Ausdruck stehen kann, linguist. Begriff, umfaßt z.B. Synonyme. (2)
Proposition: Aussage oder Behauptung, die aus einem Prädikat und einer Menge von Argumenten besteht (1) oder Texteil, der aus einer einzigen Wortkette besteht (3).
Psycholinguistik: Teilgebiet der Psychologie, das sich beschäftigt mit der Analyse von Sprachfunktionen, Sprachentwicklung, sprachlicher Kommunikation und deren Regeln und der Interdependenz von Sprache (= Sprachpsychologie).
Qualitative (Inhalts)Analyse: Inhaltsanalyse, bei der auch eine mehr oder weniger subjektive Bewertung des zu analysierenden Inhalts vorgenommen wird und die sich nicht nur auf exakt auszahlbäre Inhalte konzentriert. s.a. quantitative Inhaltsanalyse.
Quantitative (Inhalts)Analyse: Inhaltsanalyse, die sich ausschließlich auf die Vorkommenshäufigkeiten bestimmter Elemente in einem zu analysierenden Text konzentriert, z.B. auf die Vorkommenshäufigkeit bestimmter Wörter oder Zeichen, eine (subjektive) Bewertung des Inhalts findet nicht statt. s.a. qualitative Analyse.
Readability: Lesbarkeit, Verständlichkeit
Reliabilität: s. Inter-Rater-Reliabilität.
Satz: oft die Analyseeinheit bei Inhaltsanalysen, Menge von Text, die um ein Verb angeordnet ist.
Sem: Zeichen, Bestandteil/Bedeutungskomponente eines Wortes, kleineste bedeutungstragende Einheit eines Zeichens.
Semantik: Lehre von den Zeichen und ihrer Bedeutung, bzw. Lehre der menschlichen Reaktionen auf Zeichen und Symbole oder: Lehre von den Beziehungen zwischen einem Zeichen und dem dadurch Bezeichneten (3).
Semasiologie: Lehre von den Entwicklungen und den Veränderungen der Bedeutung der Zeichnung (hist. Bedeutungslehre, hist. Semantik).
Semem: Zeichen, das in seinem Kontext benutzt wird, seine Bedeutung also aus seinem Semen und Klassemen erfährt (3).
Semiotik: Teilgebiet der Semantik, das sich mit der speziellen Analyse von Zeichensystemen beschäftigt.
Semrekurrenz: Syntagmatische und/oder semantische Verkopplung meherer Lexeme infolge gleicher semantischer Merkmale (Seme). (2)
SGML: (Standard Generalized Markup Language) ist ein internationaler Standard "ISO 8879" zur strukturierten Auszeichnung von Dokumenten. Ein SGML-Dokument besteht aus drei Teilen Declaration (beschreibt formal die verwendeten Bestandteile), Document Type Definition (z.B. book, article) und Document Instance (das eigentliche Dokument).
Sonderzeichen: alle Zeichen, die keine Buchstaben oder Zahlen sind. Bei computergestützen Inhaltsanalysen sind das Satzzeichen oder andere Zeichen aus dem
Zeichensatz des PC. Beispiele: $, @, &, ©
Sprache: Bezeichnung für Mittel der kommunikativen Kundgabe mit verbalen und nonverbalen Zeichensystemen. Ein durch Kovention festgelegtes System von ausdruckshaltigen Zeichen, die das Individuum als Instrument begrifflicher Analysen
und Synthesen und als soziales Mittel der gegenseitigen Verständigung verwendet. (aus Fröhlich, W. (1991): Wörterbuch zur Psychologie. München: dtv.)
SSI: = Semantische Struktur- und Inhaltsanalyse. Inhaltsanalysetechnik, die Bedeutungen und Bedeutungsbeziehungen erfasst, wobei auch textlinguistische Prinzipien berücksichtigt werden. Manuell wird jeder Text nach strengen Regeln in eine Metasprache kodiert, die dann mit spezieller Software weiter ausgewertet wird. (s. (2), S. 236 ff.)
Stamm: s. Wortstamm.
Standard-Text: Text, bei dem alle Worte auf ihre Grundform zurückgeführt wurden, enthält keine gebeugten Worte (z.B.: aus "Häuser" wird "Haus").
Suchbegriff: Eine (von eventuell mehreren) Operationalisierung(en) einer Kategorie.
Suffix: Der am Ende stehende Teil einer Zeichenkette (Wortende). Suffixe spielen z.B. bei der Bestimmung von Abstraktheits- und Konkretsmaßen von Texten eine wichtige Rolle. Bsp: -heit, -ismus, -ung.
Synonym: Sinnverwandtes, oft bedeutungsgleiches Wort. Z.B. sind "töten", "ermorden" und "umbringen" Synonyme für den selben Sachverhalt.
Syntax: Komponente der Grammatik, die Wörter zu Phrasen und Sätzen ordnet. (1)
Systemdatei: Bei computergestützten Inhaltsanalysen: einheitliche Form der Speicherung von Texten mit klar abgegrenzten Fällen. Systemdateien bestehen aus
variabel langen Sätzen, die genau eine Texteinheit enthalten.
Tag: (engl.) Zusatzinformation in einem Text, die ergänzend eingefügt wurden, z.B. sind die (nicht sichtbaren) HTML-Codes in diesem Dokument tags.
Tagging: Linguistik: verbreitete Form der Annotation von Textmaterial, jeder Wortform wird eine eindeutige grammatische Kategorie zugeordnet. Mit entsprechender Software sehr schnell und zuverlässig zu erledigen.
Text: geordnete, zusammengehörige, Menge von Worten und Satzeichen. Kann in Texteinheiten (s.dort) zerlegt werden.
Texteinheit: Ein Text besteht aus mindestens einer Texteinheit. Diese besteht meist aus einem Satz im grammatischen Sinn. Die inhaltliche
Definition einer Texteinheit muß vom Benutzer festgelegt werden.
Textem: Wort, bei ling. Textanalysen Wort in seiner Bedeutung im Kontext.
Textlänge: Die Anzahl der Worte in einem Text, wobei Satzzeichen meist nicht mitgezählt werden.
Textsorte: Bezeichnung zur Unterscheidung verschiedener Arten von Texten. T. können z.B. sein: Zeitschriftenartikel oder Briefe, aber auch feinere Untergliederungen z.B. Tageszeitungsartikel (regional/überregional), Wochenzeitungsartikel usw.
Thesaurus: Wörterbuch.
Token: Summe aller Zeichenketten in einem Text.
Transkript: Nieder- bzw. Umschrift eines (meist gesprochenen) Textes, z. B. das Transkript eines Interviews. Die Transkription auszuwertenden Materials erfolgt meist nach strengen, projektspezifischen Regeln.
Type: Summe aller verschiedenen Zeichenketten in einem Text.
Type-Token-Ratio (TTR): Verhältnis zwischen allen verschiedenen
Zeichenketten (Types, s. dort) und der Summe aller Zeichenketten (Token, s. dort). Der Quotient liegt immer zwischen 0 und 1. Ist
der Quotient 1, kommt jede Zeichenkette nur einmal vor; ist der Quotient 0, so ist die Eingabedatei leer. Je niedriger der Quotient,
desto häufiger werden Wörter mehrfach verwendet.
Verb: syntaktische Hauptkategorie, die alle Worte umfaßt, die sich auf eine Handlung oder einen Zustand beziehen. (1)
Verständlichkeit: Lesbarkeit, Readability, Es existieren verschiedensten Formeln zur Bestimmmung, s. z.B. bei Flesh-Formel.
Vokal: Selbstlaut, a, e, i, o, u.
WinMAx: © Computerprogramm zur qualitativen Inhaltsanalyse
Wörterbuch: Andere Bezeichung für Wörterliste, Häufigkeitswörterbuch, Frequenzwörterbuch oder Diktionär.
Wort: Ein Wort innerhalb einer Texteinheit sind alle Zeichen, die vorn und hinten von mindestens einem Blank (Leerzeichen) begrenzt werden.
Wortlänge: Die Anzahl der Zeichen in einem Wort.
Wortstamm: Zeichenkette, die Teil einer anderen Zeichenkette ist. Wortstämme können Präfixe, Infixe oder Suffixe sein.
Wurzel: Grundlegendes Morphem in einem Wort oder einer Familie von Worten, besteht aus einer nicht weiter reduzierbaren Verbindung zwischen Laut und Bedeutung (1).
Zeichen: kleinstes, grundlegendstes Bestandteil eines Texts. Als Zeichen gilt der einzelne Buchstabe, die Satzzeichen, Sonderzeichen u.U. auch Leerzeichen (blanks).
Zeichenkette: eine Menge von Zeichen, die vorn und hinten von mindestens einem Leerzeichen umschlossen wird (s. Wort).
Weitere Begriffe sind erläutert z.B. in:
Mergenthaler, E. (1996): Computer assisted Content Analysis. ZUMA-Nachrichten Spezial, May 1996, S. 3-32.
und in den nachfolgenden Quellen:
(1) aus/nach Pinker, S. (1996): Der Sprachinstinkt. München: Kindler.
(2) aus/nach: Früh, W. (1998): Inhaltsanalyse. Konstanz: UVK Medien.
(3) aus/nach: Merten, K. (1995): Inhaltsanalyse. Opladen: Westdeutscher Verlag.
[Home] [Lexikon] [Software] [Literatur] [DAW] [CoAn] [Kontakt]
© ® 2002 Hendrik Berth
| 